Design of the M10 Ledger

Start with the Money Supply
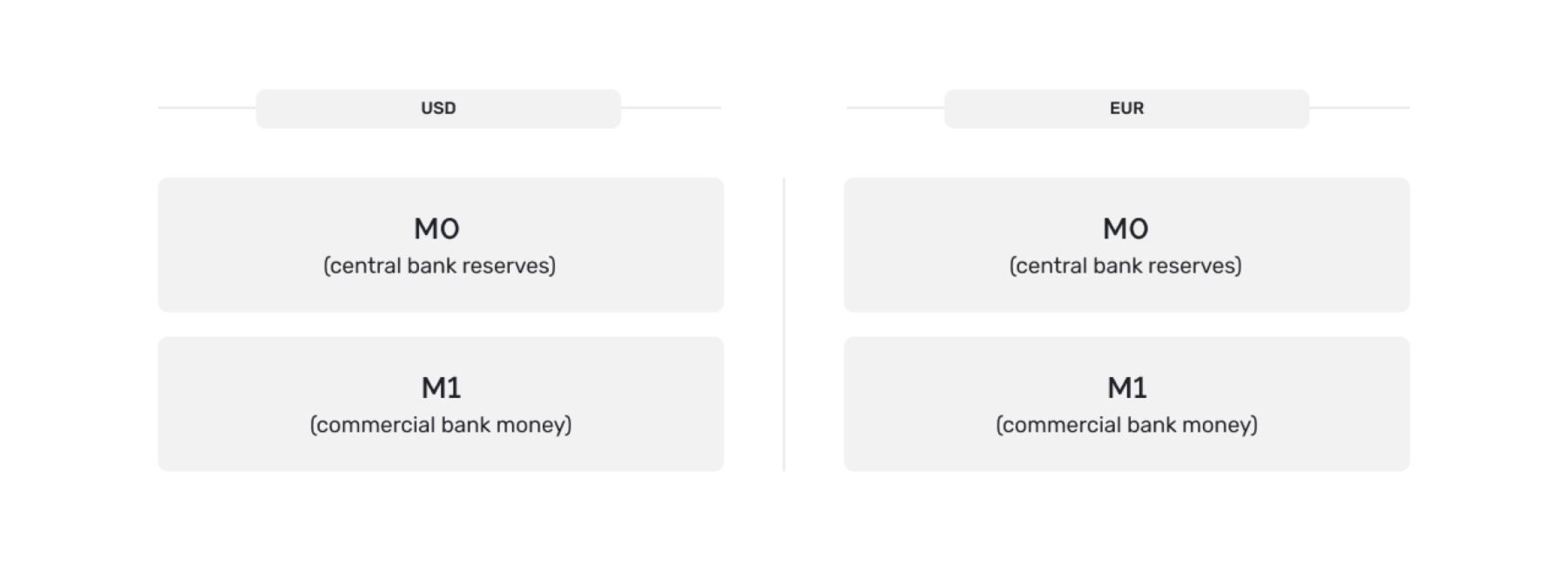
The M10 ledger is designed around money supply systems that are in use today (and have been in use ever since the advent of fractional-reserve banking). A core concept of fiat currency is that commercial banks play a role in money creation, which results in a hierarchy of currency: M0 represents currency issued directly by the central bank, M1 represents currency issued by commercial banks with the promise that it can be exchanged for "real" M0.
All of this banking stuff is a bit boring but is necessary to understand how and why M10's ledger platform is designed the way it is.
M1 + M0 = M10
When designing a digital currency ledger that supports efficient M1 payments, keeping the M0 and M1 account balances next to each other makes sense. This is because the medium of exchange for different M1 currencies is M0:
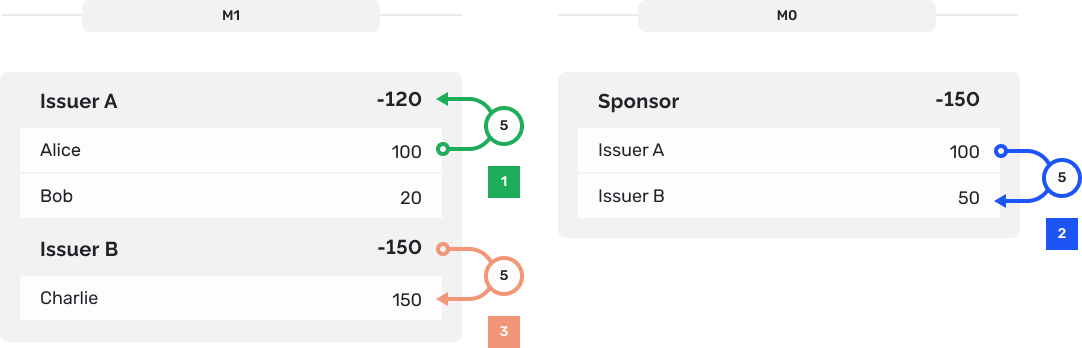
If Alice wants to pay Charlie $5, we can't simply transfer $5 from Alice's Issuer A M1 account to Charlie's Issuer B M1 account. M1 currency issued by different commercial banks is not fungible. So, the M1 issuers need to settle this transfer on the M0 ledger and if the debiting issuer doesn't have enough M0 funds, the transfer cannot be completed.
The flow described above is a use case that a CBDC solution would have to support. So, it better be implemented in a way that's efficient and fast. Also, it shouldn't require smart contracts. If modeling the fundamentals of legacy banking requires the complexity that a smart contract implementation requires (let alone the risks associated with them), then the design has been an afterthought.
Simple & Fast
The process by which we arrived at the current design of the M10 ledger is an iterative one that represents our core principles of simplicity and performance. What's a simple and performant way to represent a hierarchical ledger? An in-memory tree!
pub struct Account {
balance: u64,
children: Vec<Account>,
}This makes it trivial to implement an atomic M0/M1 payment. Assuming that account identifiers are a path (e.g "/1/200" is a unique way to identify the 200th M1 holding account under the 1st M0 issuer), account look-ups are constant-time. We're talking about load ptr offset and add/sub assembly, it's hard to simplify this further.
This is all in volatile memory; what if the ledger process crashes and we lose all state? Maybe we should persist the state to disk, but that introduces complexity and performance overhead! If we assume that the transactions themselves are persisted before they're applied, then we can recover the state by simply applying all the transactions in-order again. This is a pretty common trick that most databases use, because appending data to disk in a fault-tolerant way is much easier than synchronizing mutable data consistently.
What if we run out of memory as we add more accounts? That's not a concern, because we can fit billions of accounts in just a few GiB. Also, we're at the point in hardware capabilities where it's possible to provision servers with several terabytes of RAM.
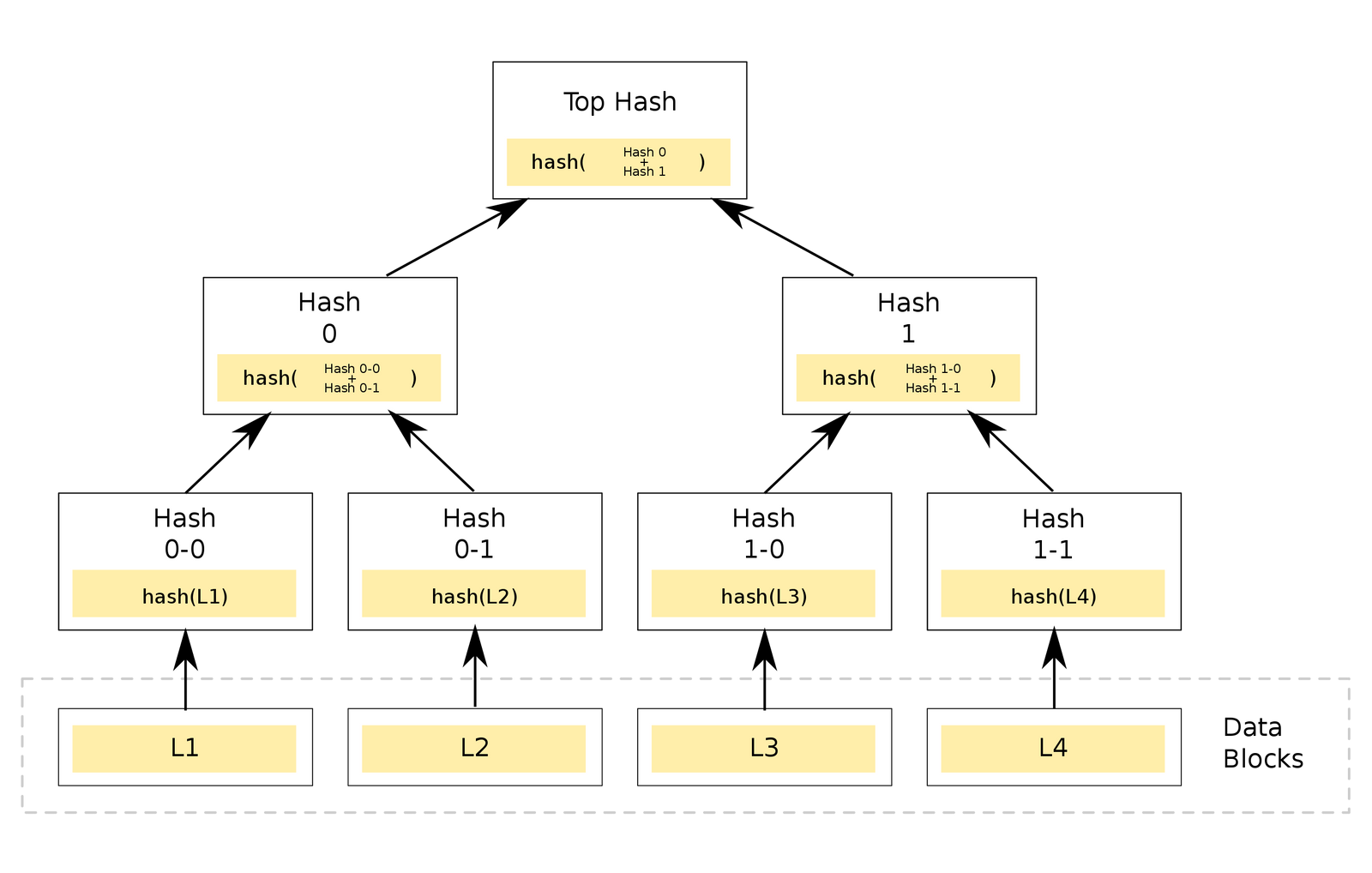
If the transaction log that's persisted on disk is corrupted (by cosmic rays, bit flips, bad actor, etc.), how can we ensure data integrity? Let's store the transaction log as a merkle tree of transaction batches instead, which allows us to stream the hashes to verification clients as well as provide on-demand merkle proofs.
What if we want to be resilient to failures at the node/rack/data-center level without any downtime or service availability issues? Let's make our solution highly available by replicating the transaction log across multiple nodes using a crash fault-tolerant (CFT) consensus algorithm like Raft or Paxos.
What if the threat model includes single or multi-node compromise by bad actors? Let's use a better consensus algorithm that's Byzantine fault tolerant (BFT) like pBFT or one of the many pBFT-derived algorithms.
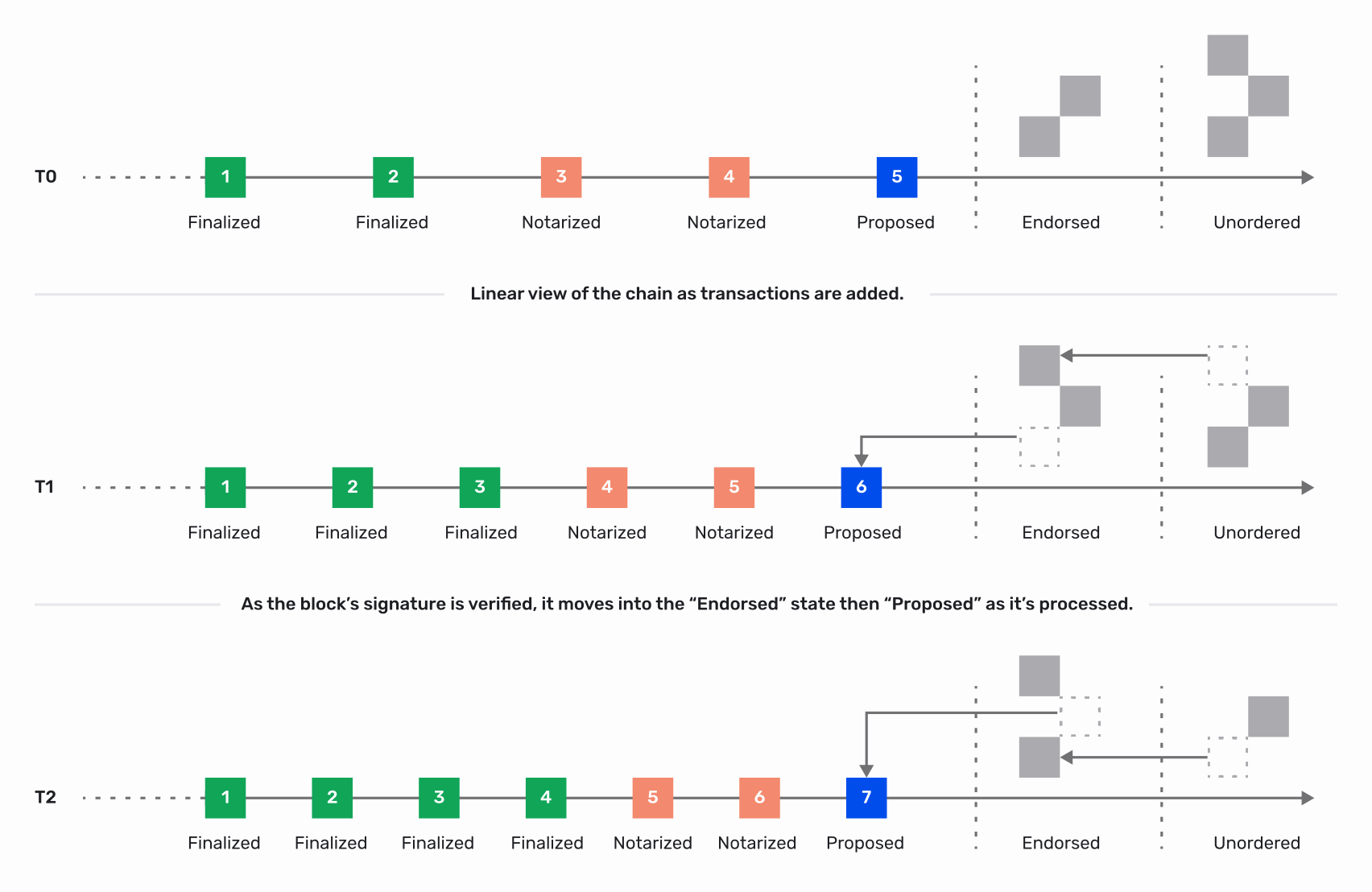
How can we scale the throughput of queries such as get_balance? Adding more voting members to the consensus algorithm could reduce the transaction throughput. So, let's introduce nodes that observe the transaction log and maintain a copy of the state in-memory but simply don't vote in the consensus protocol. We'll call them "observers".
Now we're beginning to approach the current system architecture of the M10 ledger.
Database or Blockchain?
M10 Ledger = Simple in-memory database that uses primitive data structures (lists, B-trees) + Merkle tree transaction log (for immutability, data integrity) + transaction log replication via BFT consensus algorithm (for high-availability, tolerance of bad actors).
This is, by all definitions, a blockchain but the process by which we arrived at this particular blockchain implementation is important because it demonstrates that our technology decisions are driven by the problem-space, not by marketing needs. The goal was to create a highly-available traditional database and we've accomplished that. The fact that the resulting system also resembles a blockchain is purely incidental.
